Slurm or, the “Simple Linux Utility for Resource Management,” is a software package for submitting computing workloads to a shared computer cluster. Additionally, Slurm provides tools for managing job priority so that computational resources are split fairly among users.
Source: Slurm’s Quick Start User Guide
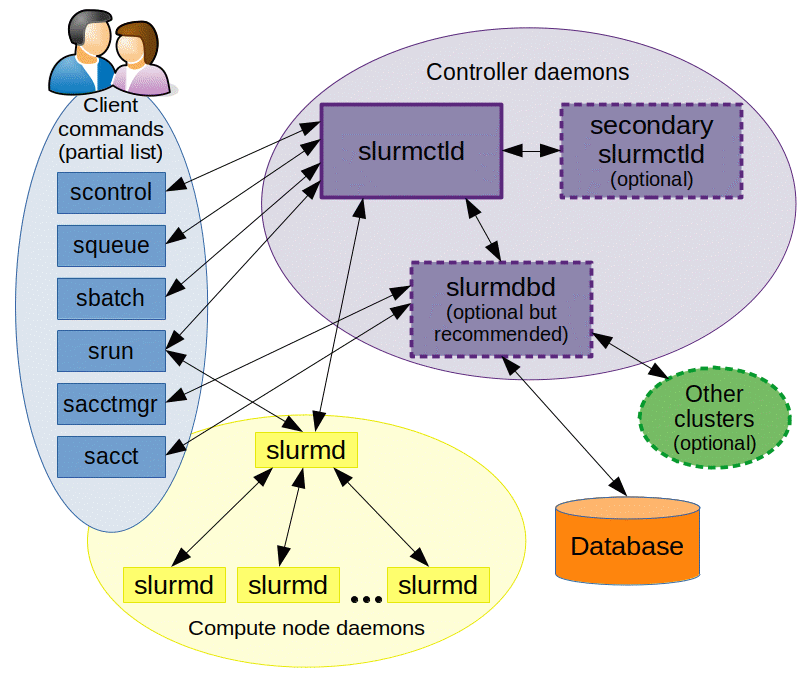
Slurm consists of the following main components:
- Client Commands
- CLI tools for interacting with the Slurm. Such as
sbatch,srun,squeue, etc. - Compute Node Daemons
- On each node
slurmdis used to monitor jobs and allocate nodes between multiple jobs - Slurm Controller
- The
slurmctldcontroller orchestrates moving jobs from the queues to the compute nodes - Databases
- Various databases are maintained to track the current queue and historical usage
Allocating Resources
Slurm manages resources (cpus, memory, gpus, etc.) using a tiered system:
- Nodes
- A single physical computer with CPUs, memory and possibly GPUs
- Partition
- Group nodes into logical (But possibly overlapping) groups. For example, the
gpupartition, contains nodes with a gpu - Jobs
- An allocation of resources for a period of time. For example, 6 CPUs and 1 Gb of memory for 1 hour
- Job Step
- Within a Job, Job Steps requests resources for a particular task
While Slurm manages this from the top-down, most users will interact from the bottom up. For example, a typical compute workload might have several job steps such as:
- Pre-processing data from raw files into a convenient format
- Analyzing the data and generating results
- Post-processing the results into graphs or generating summary statistics
Collectively, these tasks form a single Job that requires a certain amount of computing resources to complete. For example, a job might request 8 CPUs, 10 Gb of memory, and 1 GPU for 3 hours.
We could also split these tasks across several jobs, or use a Heterogeneous Job, to tailor our requests for each job step.
The user submits this job to a particular partition to satisfy the job’s computing needs. This job requires a GPU, and it needs a partition with GPUs (i.e., gpu). Other jobs may need lots of memory or a longer run time and should be submitted accordingly. For more information about Arjuna’s partitions see Cluster Architecture.
Once submitted to a partition, the Job waits in the Slurm queue until Slurm releases it to run on one or more nodes. Slurm releases jobs based on their priority computed from the user’s fair share. Users using less than their “fair share” have a higher priority than users using more than their “fair share.”
Carefully crafting the resources requested by a job ensures that it is submitted as soon as possible and does not get delayed waiting for resources that it does not need.
Accounting
Usage on Slurm is billed based on Trackable RESources (TRES). Currently, using 1 CPU for 1 hour consumes 1 TRES-hour. A job that used 32 CPUs for 2 hours is billed for 64 TRES-hours (32 * 2 = 64).
Memory is billed based on the number of CPUs on the node divided by the total memory. Jobs may use up to this amount at no additional cost but are billed additional TRES above this limit. For example, on the cpu partition, each CPU gets 0.435GiB of memory. A Job that requests 2 CPUs and 512MiB of memory is billed 2 TRES per hour (max(2, 0.5 * 0.435) = 2).
Slurm uses a system of units based on a power of 2, not 10. Thus 1G of memory is 1,073,741,824 bytes, not 1,000,000,000 bytes
This usage is billed to the user’s default account. To see your accounts run sacctmgr show user $(whoami) WithAssoc
sacctmgr show user $(whoami) WithAssoc WOPLimits
User Def Acct Admin Cluster Account Partition Share MaxJobs MaxNodes MaxCPUs MaxSubmit MaxWall MaxCPUMins QOS Def QOS
---------- ---------- --------- ---------- ---------- ---------- --------- ------- -------- -------- --------- ----------- ----------- -------------------- ---------
jdoe example None arjuna example highmem 1
jdoe example None arjuna example-2 cpu 1
jdoe example None arjuna example idle 1
jdoe example None arjuna example debug 1
Here we can see that jdoe has example as their default account and can submit jobs to the highmem, cpu, idle and debug partitions. Our user jdoe does not have an entry for the gpu partition, so they can not submit to the gpu partition.
To submit to the cpu partition, jdoe needs to use their example-2 account. They can not submit to cpu using their default account. Use the --account flag to change the account used to submit a job. See sbatch for more information.
Additional Resources
See the High-Performance Computing section for more information.